
What LatamGPT Knows (and Doesn’t): An Early Benchmark Preview
Published:
In February 2026, LatamGPT was presented to a wave of regional enthusiasm: the first open large language model built from and for Latin America and the Caribbean, coordinated by Chile's CENIA and more than sixty institutions across the region. The promise was sovereignty and cultural relevance—moving Latin America from a consumer of foreign models to a producer of its own. When the open weights landed on June 1, 2026, though, they came without a single benchmark number, and the technical report hasn't appeared yet. As someone who has spent years working with language models, I was curious enough not to wait—so I ran an early, independent evaluation on a set of Spanish-only tasks plus the cultural benchmarks CENIA just released. Treat this as a preview, to be confirmed when the official numbers arrive. The question I wanted to answer is simple: what does LatamGPT actually know that other models don't?
What LatamGPT is, and what I compared it to
LatamGPT starts from Meta's Llama 3.1 70B (the base model) and adapts it in two stages: continued pre-training (CPT) on roughly 230 billion words of permissioned regional text—Spanish, Portuguese and Indigenous languages—followed by supervised fine-tuning (SFT) for instruction following. The released model, then, is an instruct model—and that shapes the comparison: the fair yardstick isn't GPT-5 or some abstract ideal, but other instruct models of similar or smaller size. I line it up against three: Meta's own Llama 3.1 70B Instruct (built from the very same base), and two newer, smaller models, Gemma 4 31B and Qwen3.6 27B. All four are instruct models, evaluated the same way.
Here's how the four models stack up across every benchmark I ran:
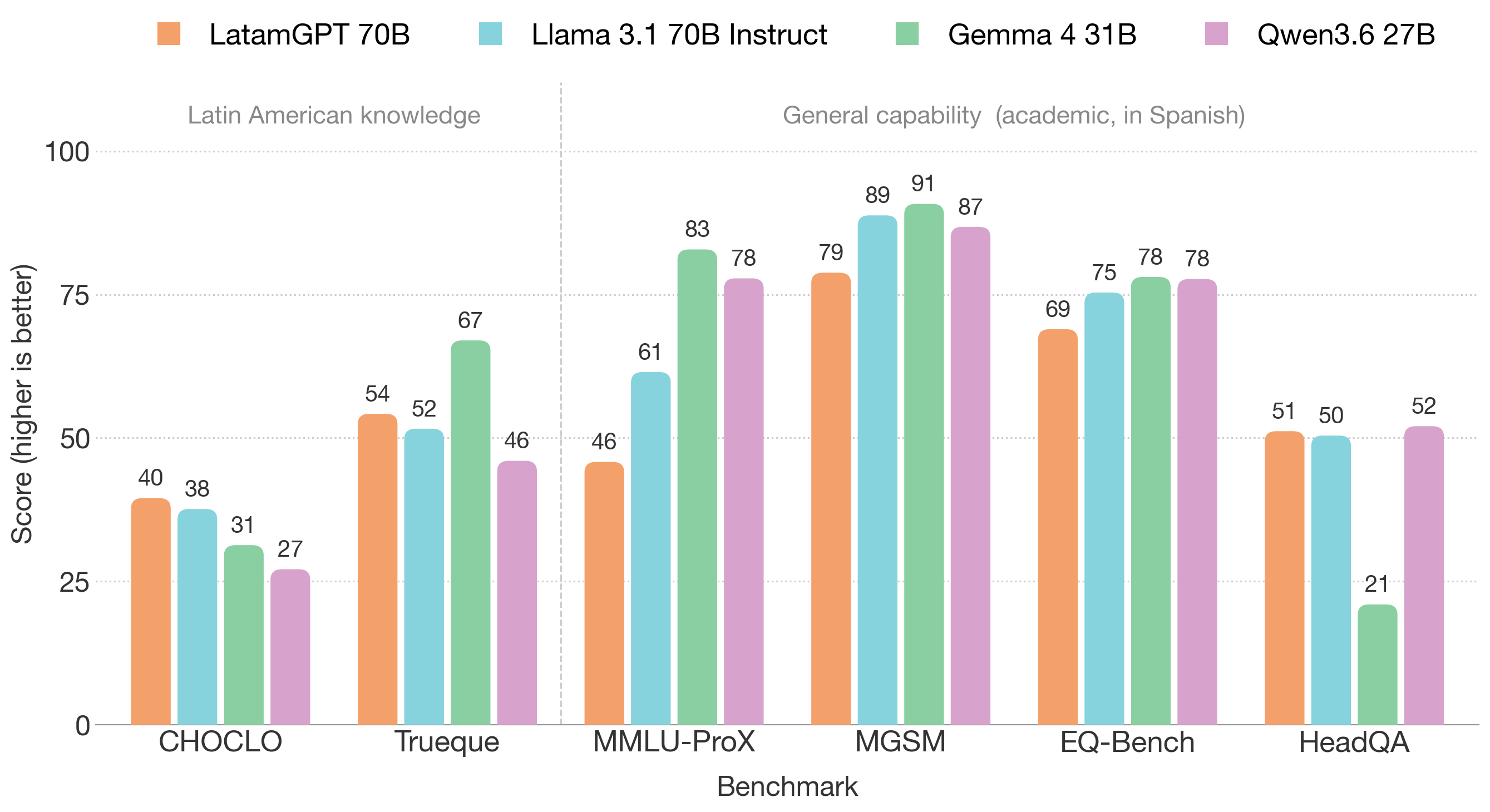
Where it pays off: Latin American knowledge
If LatamGPT knows anything other models don't, this is where it should show: the benchmarks built for the region. CHOCLO—a CENIA release from the same Latam-GPT effort, openly available on Hugging Face—is a 104,847-question benchmark of Latin American cultural knowledge (food, flora and fauna, geography, traditions, public figures). I score it with an LLM judge that rules each answer equivalent to the reference answer or not; the number is the share judged equivalent (judging details in the note at the end). Here LatamGPT comes first: 39.5% of its answers are judged equivalent, ahead of Llama 3.1 Instruct (37.6) and well ahead of the newer models (Gemma 4 31B at 31.3, Qwen3.6 27B at 27.1)—and that lead holds at every difficulty level.
This is the encouraging result. Latin American cultural knowledge doesn't fall out of scale or recency—Gemma and Qwen are newer and strong, and they still trail here, because the facts about a Chilean dish or a Peruvian tradition were simply never in their training data. You cannot reason your way to knowledge you were never shown. The regional corpus put that knowledge in, and CHOCLO can see it.
It doesn't win every cultural test, though. Trueque—a smaller, human-reviewed collaborative benchmark (500 questions in this beta, scored the same way)—is more mixed. LatamGPT again beats Llama 3.1 Instruct (54.2 vs. 51.6) and Qwen (46.0), but Gemma 4 31B comes out on top, 67.0 to 54.2. On CHOCLO's long-tail, machine-generated facts the regional data is decisive; on Trueque's broader, human-reviewed questions, a stronger general model can still pull ahead.
Both cultural benchmarks side by side, with CHOCLO broken out by difficulty:
| Binary semantic equivalence (%) | LatamGPT 70B | Llama 3.1 70B | Gemma 4 31B | Qwen3.6 27B |
|---|---|---|---|---|
| CHOCLO — Overall (n = 104,847) | 39.5 | 37.6 | 31.3 | 27.1 |
| — Fácil (easy) | 59.8 | 57.1 | 48.4 | 45.1 |
| — Intermedia (intermediate) | 33.9 | 32.3 | 24.3 | 20.7 |
| — Difícil (hard) | 24.9 | 23.6 | 21.3 | 15.6 |
| Trueque — Overall (n = 500, beta) | 54.2 | 51.6 | 67.0 | 46.0 |
Where it falls behind: general ability
Now the flip side. Unlike English, there's no standard, widely-agreed benchmark suite for Spanish LLMs, so I assembled one from openly available tasks that mirror what's typically reported for English models—and on these, LatamGPT lands below the three comparison models. On MMLU-ProX (es)—the cleanest, fully-Spanish reasoning set—it scores 45.8, against 61.5 for Llama 3.1 Instruct and over 80 for Gemma. Grade-school math (MGSM) comes in at 78.8 (vs. 88.8 for Llama Instruct); emotional-reasoning EQ-Bench at 69.0 (vs. 75.4). The one general task where it's even is HeadQA, a medical-exam QA set (51.2 vs. 50.4).
The exact general-benchmark numbers:
| General benchmark (Spanish) | Shots | n | Metric | LatamGPT 70B | Llama 3.1 70B | Gemma 4 31B | Qwen3.6 27B |
|---|---|---|---|---|---|---|---|
| MMLU-ProX (es) | 5 | 11,759 | EM | 45.81 | 61.48 | 82.86 | 77.82 |
| MGSM native-CoT (es) | 8 | 250 | EM | 78.80 | 88.80 | 90.80 | 86.80 |
| EQ-Bench (es) | 0 | 168 | EQ-Bench | 68.95 | 75.35 | 78.06 | 77.70 |
| HeadQA (es) | 0 | 2,742 | Acc | 51.17 | 50.40 | 20.97 | 52.04 |
EM = exact match, Acc = accuracy; EQ-Bench uses its own 0–100 scale. Bold marks the best score per row. All four are instruct models; the "Llama 3.1 70B" column is the Instruct checkpoint (see the note at the end). Gemma's HeadQA score is set aside as an artifact.
Why the gap?
So the released model knows the region better than any of the others, but trails them on general academics. Why? Continued pre-training is deceptively hard: you nudge a finished model's weights toward a new data distribution, and it has no obligation to keep its old abilities intact while you do. The classic failure mode is catastrophic forgetting—a model shedding what it knew as it learns something new—a real, well-studied risk whenever you keep training a finished model, and one I've studied first-hand, in continual learning and continued pre-training. That makes it the prime suspect for LatamGPT's drop in general ability, whether it crept in during the CPT stage, the SFT stage, or both.
I can't prove it, though. Pinning the gap on forgetting cleanly would need the CPT-only checkpoint—before instruction tuning—and that hasn't been released, so for now it stays a hypothesis. Still, one detail suggests the drop is at least partly real. Instruction tuning, if anything, slightly lifts MMLU-style scores rather than lowering them—for instance, Llama 3.1 70B goes from 79.3 (base) to 83.6 (instruct) on MMLU. So LatamGPT's instruction tuning should have nudged its score up, not down. Yet on MMLU-ProX it lands at 45.8—about 16 points below Llama 3.1 Instruct's 61.5, from the same base. A deficit that large, in the opposite direction from what tuning does, points back to the continued-pre-training stage. Against the newer models, it's partly a different story: Gemma 4 and Qwen3.6 are roughly two years newer than LatamGPT's 2024-era base, so some of that gap is just vintage. The technical report—and ideally the intermediate, CPT-only weights—would settle it.
So what’s the real contribution?
Step back, and the early numbers raise a question I find more interesting than any single score: what is the durable contribution here—the model, or the data? Open weights are superseded fast—strong open models keep arriving at a steady clip—so that's just the cadence of the field. But the regional corpus and benchmarks like CHOCLO are the kind of asset that doesn't expire. A few questions worth sitting with as a community: Does the region need to train a model, or to curate data that can shape any model? CHOCLO already shows where the value concentrates—the Latin American knowledge it encodes is exactly where LatamGPT pulls ahead. That signal may be more powerful as a portable resource—usable through retrieval-augmented generation, in-context examples, lighter and more cost-effective fine-tuning, or as a callable cultural-competence skill for agentic systems—than frozen into one set of weights.
None of this is a verdict—it's an early read, and the official report may sharpen or overturn parts of it. What's already clear is what LatamGPT accomplished: a large, multi-country collaboration that assembled permissioned regional data at scale—including Portuguese and Indigenous languages commercial models largely ignore—built real training capacity in the region, and produced the model that best captures Latin American cultural knowledge today. Much of that never shows up in a benchmark score, and it matters. This is a first release, a version 1.0 with plenty of room to grow, and the data behind it is a real public good. If models are the engines, data defines the terrain—and the most durable thing the region can do is encode its terrain deeply enough that every model, this year's or next year's, has to learn it.
A note on the numbers
A few caveats. Every benchmark is in Spanish—both the answer-generation and the judging prompts. Academic benchmarks ran on EleutherAI's lm-evaluation-harness; CHOCLO and Trueque were scored with DeepEval using one external judge (gpt-5.4-mini) applied identically to every model, so those columns are comparable. CHOCLO's native evaluation is a hybrid (lexical, embedding, LLM-as-judge); I report only the LLM-as-judge part, as a binary equivalent/not call, and since the repos don't fully document their judging, treat the absolute CHOCLO/Trueque scores as internally consistent rather than official. All four models are instruct models; the Llama baseline is Llama-3.1-70B-Instruct. LatamGPT itself is Llama-3.1-70B (base) + CPT + SFT; the CPT-only checkpoint isn't public, so I compare released instruct models and can't isolate the CPT step. MMLU-ProX (es) is my MMLU number because it's fully Spanish. Gemma 4 31B and Qwen3.6 27B ran with reasoning ("thinking") off. Every result is a single run, except Gemma 4 31B on HeadQA, which I ran three times—≈21 (below chance) each time, perhaps an evaluation artifact.
References
- LatamGPT model card: latam-gpt/Llama-3.1-70B-LatamGPT-SFT-1.0 and the Latam-GPT organization on Hugging Face.
- CHOCLO dataset: latam-gpt/CHOCLO.
- Trueque dataset: latam-gpt/Trueque-Benchmark-beta-0.1.
- Omar U. Flórez (2026). LatamGPT open-weights release announcement (June 1, 2026).
- CENIA (2026). CHOCLO and Trueque benchmarks — release announcement (LinkedIn).
- France24 (2026). Latam-GPT: a Latin American AI to combat US-centric bias.
- AI Business (2026). Meet Latam-GPT, the New Open Source AI Model for Latin America (source for the ~230 billion words / 300 billion tokens figure, attributed to CENIA).
- Brookings (2026). Latam-GPT and the search for AI sovereignty.
- Rest of World (2025). Latin America is building LatamGPT to rival ChatGPT.
- Vladimir Araujo, Andrés Villa, Marcelo Mendoza, Marie-Francine Moens, and Alvaro Soto. 2021. Augmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations. EMNLP 2021.
- Vladimir Araujo, Marie-Francine Moens, and Tinne Tuytelaars. 2024. Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models. Findings of EMNLP 2024.
- EleutherAI. lm-evaluation-harness (academic benchmark evaluation).
- Confident AI. DeepEval (LLM-as-judge evaluation, used for CHOCLO and Trueque).
Co-Authored-By: Claude