
Lo que LatamGPT sabe (y lo que no): una primera mirada a sus benchmarks
En febrero de 2026, se presentó LatamGPT en medio de mucho entusiasmo en la región: el primer modelo de lenguaje grande y abierto hecho desde y para América Latina y el Caribe, coordinado por el CENIA de Chile junto a más de sesenta instituciones. La promesa era soberanía y relevancia cultural: dejar de ser solo consumidores de modelos extranjeros para pasar a producir los propios. Pero cuando los pesos abiertos salieron el 1 de junio de 2026, llegaron sin una sola cifra de benchmark, y el reporte técnico todavía no aparece. Como alguien que lleva años trabajando con modelos de lenguaje, me ganó la curiosidad y no quise esperar: corrí una evaluación temprana e independiente sobre un conjunto de tareas en español, más los benchmarks culturales que el CENIA acaba de publicar. Tómalo como un adelanto, a confirmar cuando salgan las cifras oficiales. La pregunta que quería responder es sencilla: ¿qué sabe LatamGPT que los demás modelos no?
Qué es LatamGPT y contra qué lo comparé
LatamGPT parte del Llama 3.1 70B de Meta (el modelo base) y lo adapta en dos etapas: continued pre-training (CPT) sobre unas 230 mil millones de palabras de texto regional—en español, portugués y lenguas indígenas—y después un supervised fine-tuning (SFT) para que siga instrucciones. Es decir, el modelo que se liberó es un modelo instruct, y eso marca la comparación: la vara justa no es GPT-5 ni un ideal abstracto, sino otros modelos instruct de tamaño parecido o menor. Lo comparo contra tres: el propio Llama 3.1 70B Instruct de Meta (que sale de la misma base) y dos modelos más nuevos y pequeños, Gemma 4 31B y Qwen3.6 27B. Los cuatro son modelos instruct, evaluados de la misma forma.
Así se comparan los cuatro modelos en todos los benchmarks que corrí:
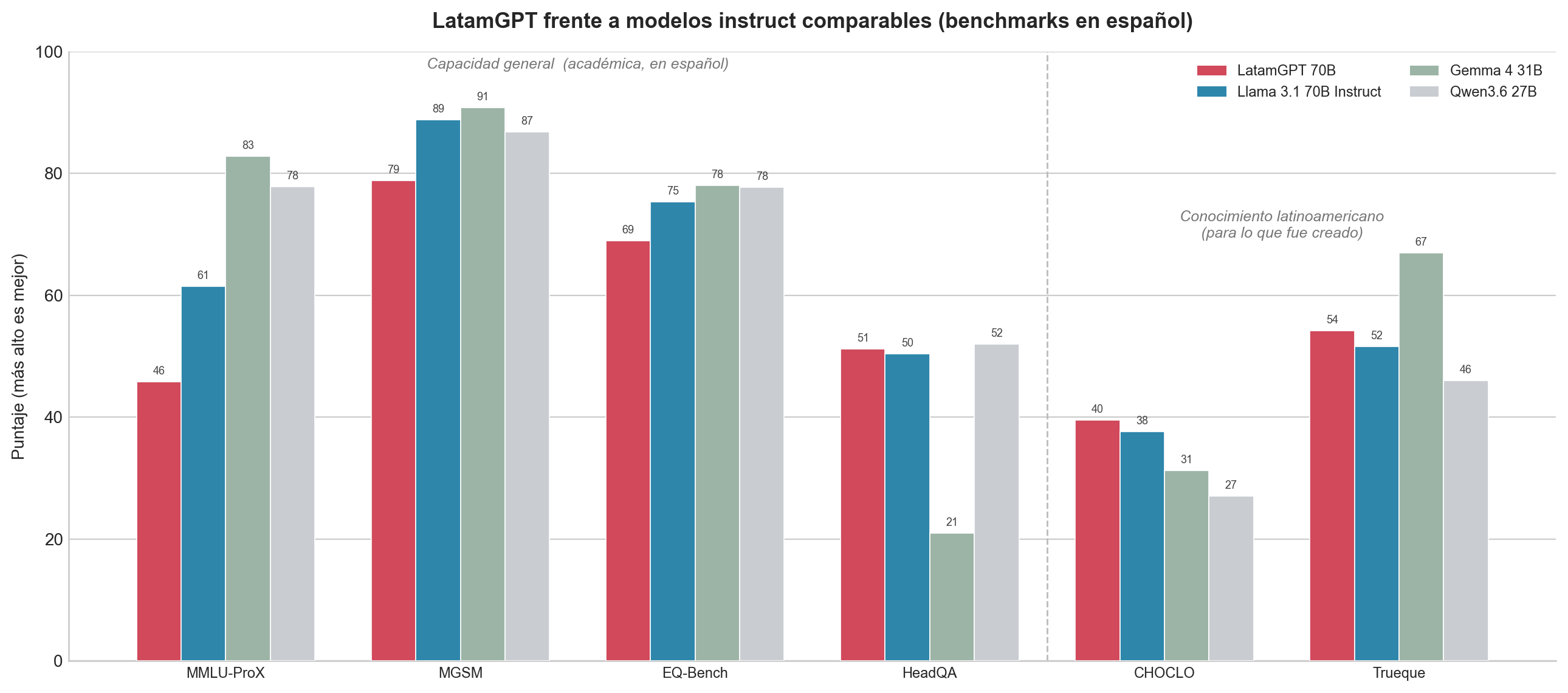
Donde rinde: el conocimiento latinoamericano
Si LatamGPT sabe algo que los demás no, es aquí donde tendría que notarse: en los benchmarks hechos para la región. CHOCLO—un dataset que el CENIA liberó dentro del mismo esfuerzo de Latam-GPT, disponible abiertamente en Hugging Face—tiene 104,847 preguntas de conocimiento cultural latinoamericano (comida, flora y fauna, geografía, tradiciones, figuras públicas). Lo evalúo con un LLM como juez que decide si cada respuesta es o no semánticamente equivalente a la de referencia; el número es la proporción de respuestas que da por equivalentes (los detalles del juez van en la nota al final). Aquí LatamGPT queda primero: el 39.5% de sus respuestas se juzgan equivalentes, por encima de Llama 3.1 Instruct (37.6) y bastante por delante de los modelos más nuevos (Gemma 4 31B con 31.3, Qwen3.6 27B con 27.1), y esa ventaja se sostiene en todos los niveles de dificultad.
Este es el resultado alentador. El conocimiento cultural latinoamericano no aparece solo por escala ni por ser más reciente: Gemma y Qwen son más nuevos y potentes, y aun así se quedan atrás aquí, porque los datos sobre un plato chileno o una tradición peruana simplemente nunca estuvieron en su entrenamiento. No se puede razonar hacia un conocimiento que nunca se vio. El corpus regional metió ese conocimiento, y CHOCLO lo detecta.
Pero no gana todas las pruebas culturales. Trueque—un benchmark de QA latinoamericano más pequeño, colaborativo y revisado por humanos (500 preguntas en esta beta, evaluado igual)—cuenta una historia más matizada. LatamGPT otra vez le gana a Llama 3.1 Instruct (54.2 vs. 51.6) y a Qwen (46.0), pero Gemma 4 31B se queda con el primer lugar, 67.0 contra 54.2. En los datos de cola larga y generados automáticamente de CHOCLO, lo regional es decisivo; en las preguntas más amplias y revisadas por humanos de Trueque, un modelo general más fuerte todavía se puede imponer.
Los dos benchmarks culturales, lado a lado, con CHOCLO desglosado por dificultad:
| Equivalencia semántica binaria (%) | LatamGPT 70B | Llama 3.1 70B | Gemma 4 31B | Qwen3.6 27B |
|---|---|---|---|---|
| CHOCLO — Total (n = 104,847) | 39.5 | 37.6 | 31.3 | 27.1 |
| — Fácil | 59.8 | 57.1 | 48.4 | 45.1 |
| — Intermedia | 33.9 | 32.3 | 24.3 | 20.7 |
| — Difícil | 24.9 | 23.6 | 21.3 | 15.6 |
| Trueque — Total (n = 500, beta) | 54.2 | 51.6 | 67.0 | 46.0 |
Donde se queda atrás: la capacidad general
Ahora el otro lado. A diferencia del inglés, no hay un conjunto de benchmarks estándar y consensuado para LLMs en español, así que armé uno con tareas disponibles abiertamente que reflejan lo que se suele reportar para los modelos en inglés—y en estas, LatamGPT queda por debajo de los tres modelos de comparación. En MMLU-ProX (es)—el benchmark de razonamiento más limpio y completamente en español del conjunto—saca 45.8, contra 61.5 de Llama 3.1 Instruct y más de 80 de Gemma. En matemática escolar (MGSM) llega a 78.8 (vs. 88.8 de Llama Instruct); en razonamiento emocional (EQ-Bench), a 69.0 (vs. 75.4). La única tarea general donde quedan parejos es HeadQA, un examen médico tipo QA (51.2 vs. 50.4).
Las cifras exactas de los benchmarks generales:
| Benchmark general (español) | Shots | n | Métrica | LatamGPT 70B | Llama 3.1 70B | Gemma 4 31B | Qwen3.6 27B |
|---|---|---|---|---|---|---|---|
| MMLU-ProX (es) | 5 | 11,759 | EM | 45.81 | 61.48 | 82.86 | 77.82 |
| MGSM native-CoT (es) | 8 | 250 | EM | 78.80 | 88.80 | 90.80 | 86.80 |
| EQ-Bench (es) | 0 | 168 | EQ-Bench | 68.95 | 75.35 | 78.06 | 77.70 |
| HeadQA (es) | 0 | 2,742 | Acc | 51.17 | 50.40 | 20.97 | 52.04 |
EM = exact match, Acc = accuracy; EQ-Bench usa su propia escala 0–100. En negrita, el mejor puntaje de cada fila. Los cuatro son modelos instruct; la columna "Llama 3.1 70B" es el checkpoint Instruct (ver la nota al final). El puntaje de Gemma en HeadQA queda de lado, como artefacto.
¿Por qué la brecha?
Entonces el modelo liberado conoce la región mejor que cualquiera de los otros, pero queda atrás en lo académico general. ¿Por qué? El continued pre-training es engañosamente difícil: uno empuja los pesos de un modelo ya terminado hacia una nueva distribución de datos, y el modelo no tiene ninguna obligación de conservar intactas sus habilidades anteriores mientras tanto. El modo de falla clásico es el catastrophic forgetting—un modelo que va perdiendo lo que sabía a medida que aprende algo nuevo—, un riesgo real y muy estudiado cada vez que uno sigue entrenando un modelo ya terminado, y algo que estudié de primera mano, en continual learning y continued pre-training. Eso lo vuelve el principal sospechoso de la caída de LatamGPT en capacidad general, ya sea que se haya colado en la etapa de CPT, en la de SFT, o en ambas.
Aunque no lo puedo probar. Para atribuir la brecha al forgetting de forma limpia haría falta el checkpoint de solo-CPT—antes del instruction tuning—, y ese no se liberó, así que por ahora queda en hipótesis. Aun así, un detalle sugiere que la caída es, al menos en parte, real. El instruction tuning, si acaso, sube un poco los puntajes tipo MMLU en lugar de bajarlos: por ejemplo, Llama 3.1 70B pasa de 79.3 (base) a 83.6 (instruct) en MMLU. Así que el instruction tuning de LatamGPT debería haberle subido el puntaje, no bajárselo. Y sin embargo, en MMLU-ProX queda en 45.8—unos 16 puntos por debajo del 61.5 de Llama 3.1 Instruct, partiendo de la misma base. Una diferencia tan grande, y en sentido contrario a lo que hace el tuning, apunta de vuelta a la etapa de continued pre-training. Frente a los modelos más nuevos la historia es en parte otra: Gemma 4 y Qwen3.6 son como dos años más nuevos que la base Llama de 2024 de la que parte LatamGPT, así que parte de esa brecha es pura cuestión de época. El reporte técnico—e idealmente los pesos intermedios, los de solo-CPT—lo dejarían claro.
Entonces, ¿cuál es la contribución real?
Si damos un paso atrás, las cifras tempranas plantean una pregunta que me parece más interesante que cualquier puntaje suelto: ¿cuál es el aporte que perdura aquí—el modelo o los datos? Los pesos abiertos quedan obsoletos rápido—no dejan de salir modelos abiertos potentes—, así avanza el campo. Pero el corpus regional y benchmarks como CHOCLO son el tipo de activo que no caduca. Algunas preguntas que vale la pena dejar dando vueltas, como comunidad: ¿la región necesita entrenar un modelo, o curar datos que puedan moldear a cualquier modelo? CHOCLO ya muestra dónde se concentra el valor: el conocimiento latinoamericano que codifica es justo donde LatamGPT saca ventaja. Esa señal puede rendir más como recurso portátil—usable vía retrieval-augmented generation, ejemplos en contexto, un fine-tuning más económico, o como una skill de competencia cultural que un sistema de agentes pueda invocar—que congelada en un solo conjunto de pesos.
Nada de esto es un veredicto: es una lectura temprana, y el reporte oficial puede afinarla o desmentir partes. Lo que ya está claro es lo que logró LatamGPT: una colaboración grande y multinacional que juntó datos regionales con licencia a gran escala—incluyendo portugués y lenguas indígenas que los modelos comerciales suelen ignorar—, que construyó capacidad real de entrenamiento en la región y que produjo el modelo que mejor captura el conocimiento cultural latinoamericano hoy. Mucho de eso no aparece en ningún puntaje de benchmark, y sí que importa. Es un primer lanzamiento, una versión 1.0 con mucho margen para crecer, y los datos detrás son un bien público de verdad. Si los modelos son los motores, los datos definen el terreno—y lo más perdurable que puede hacer la región es dejar su terreno tan bien codificado que todo modelo, el de este año o el del próximo, no tenga más remedio que aprenderlo.
Una nota sobre los números
Algunas aclaraciones. Todos los benchmarks están en español—tanto los prompts para generar las respuestas como los de evaluación. Los benchmarks académicos los corrí con lm-evaluation-harness de EleutherAI; CHOCLO y Trueque los evalué con DeepEval, usando un único juez externo (gpt-5.4-mini) aplicado igual a todos los modelos, así que esas columnas son comparables entre sí. La evaluación nativa de CHOCLO es híbrida (léxica, por embeddings y con un LLM como juez); yo reporto solo la parte del LLM como juez, como una decisión binaria de equivalente/no equivalente, y como los repos no documentan del todo cómo evalúan, conviene leer los puntajes absolutos de CHOCLO/Trueque como internamente consistentes más que como oficiales. Los cuatro son modelos instruct; la base de comparación de Llama es Llama-3.1-70B-Instruct. LatamGPT, en sí, es Llama-3.1-70B (base) + CPT + SFT; el checkpoint de solo-CPT no es público, así que comparo los modelos instruct ya liberados y no puedo aislar la etapa de CPT. Uso MMLU-ProX (es) como número de MMLU porque está completamente en español. Gemma 4 31B y Qwen3.6 27B corrieron con el reasoning ("thinking") desactivado. Cada resultado viene de una sola corrida, salvo Gemma 4 31B en HeadQA, que corrí tres veces—≈21 (por debajo del azar) cada vez, quizás un artefacto de evaluación.
Referencias
- Ficha del modelo LatamGPT: latam-gpt/Llama-3.1-70B-LatamGPT-SFT-1.0 y la organización Latam-GPT en Hugging Face.
- Dataset CHOCLO: latam-gpt/CHOCLO.
- Dataset Trueque: latam-gpt/Trueque-Benchmark-beta-0.1.
- Omar U. Flórez (2026). Anuncio del lanzamiento de los pesos abiertos de LatamGPT (1 de junio de 2026).
- CENIA (2026). Benchmarks CHOCLO y Trueque — anuncio de lanzamiento (LinkedIn).
- France24 (2026). Latam-GPT: a Latin American AI to combat US-centric bias.
- AI Business (2026). Meet Latam-GPT, the New Open Source AI Model for Latin America (fuente de la cifra de ~230 mil millones de palabras / 300 mil millones de tokens, atribuida al CENIA).
- Brookings (2026). Latam-GPT and the search for AI sovereignty.
- Rest of World (2025). Latin America is building LatamGPT to rival ChatGPT.
- Vladimir Araujo, Andrés Villa, Marcelo Mendoza, Marie-Francine Moens, and Alvaro Soto. 2021. Augmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations. EMNLP 2021.
- Vladimir Araujo, Marie-Francine Moens, and Tinne Tuytelaars. 2024. Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models. Findings of EMNLP 2024.
- EleutherAI. lm-evaluation-harness (evaluación de benchmarks académicos).
- Confident AI. DeepEval (evaluación con LLM como juez, usada para CHOCLO y Trueque).
Co-Authored-By: Claude